One of such models is BERT. It is primarily known for being able to construct embeddings which can very accurately represent text information and store semantic meanings of long text sequences. As a result, BERT embeddings became widely used in machine learning. Understanding how BERT builds text representations is crucial because it opens the door for tackling a large range of tasks in NLP.
In this article, we will refer to the original BERT paper and have a look at BERT architecture and understand the core mechanisms behind it. In the first sections, we will give a high-level overview of BERT. After that, we will gradually dive into its internal workflow and how information is passed throughout the model. Finally, we will learn how BERT can be fine-tuned for solving particular problems in NLP.
High level overview
Transformer’s architecture consists of two primary parts: encoders and decoders. The goal of stacked encoders is to construct a meaningful embedding for an input which would preserve its main context. The output of the last encoder is passed to inputs of all decoders trying to generate new information.
BERT is a Transformer successor which inherits its stacked bidirectional encoders. Most of the architectural principles in BERT are the same as in the original Transformer.
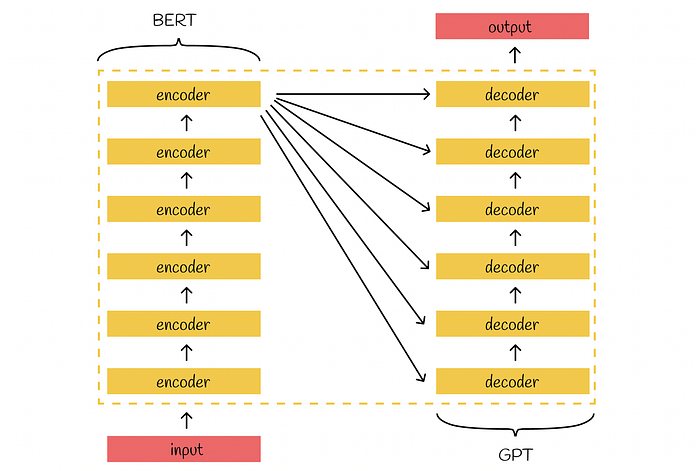
Transformer architecture
BERT versions
There exist two main versions of BERT: base and large. Their architecture is absolutely identical except for the fact that they use different numbers of parameters. Overall, BERT large has 3.09 times more parameters to tune, compared to BERT base.